
The FMCG landscape has reached a tipping point.
On one side, margins are under pressure from rising operational costs. On the other, the room for price increases has effectively vanished.
Most brands try to solve this with the “Traditional Loop”: fixed territories and rigid visit schedules.
The problem? It’s a contact strategy based on geography, not opportunity. It treats every store as an equal priority, regardless of its actual performance at that moment.
To grow, you don’t need more visits; you need smarter triggers. Here’s how to use EPOS (Electronic Point of Sale) data to turn your field sales into a precision strike force.
The power of EPOS data
Traditional field sales operate on a loop. Reps visit Store A because it’s Tuesday, not because Store A needs them.
The result? High OpEx, low ROI.
By leveraging store-level Sell-out data, you stop asking “Who should we visit?” and start asking “Where is the money leaking?”
Epos data allows you to identify where you add the most value right now.
Tracking patterns, identifying anomalies
We didn’t reinvent the wheel; we borrowed one from the banking industry.
Banks use models to spot a 1€ theft in a sea of millions. We apply the same logic to your shelves:
Clustering: We group stores with identical sales patterns.
Tracking: We monitor them in real-time.
Detection: If Store #402 deviates from its “cluster” (even by a few units), a red flag goes up.
This isn’t just “reporting.” It’s predictive. We translate these deviations into Lost Sales Value. We don’t just tell you there’s a problem; we tell you exactly how many Euros you’re losing every hour you don’t act.
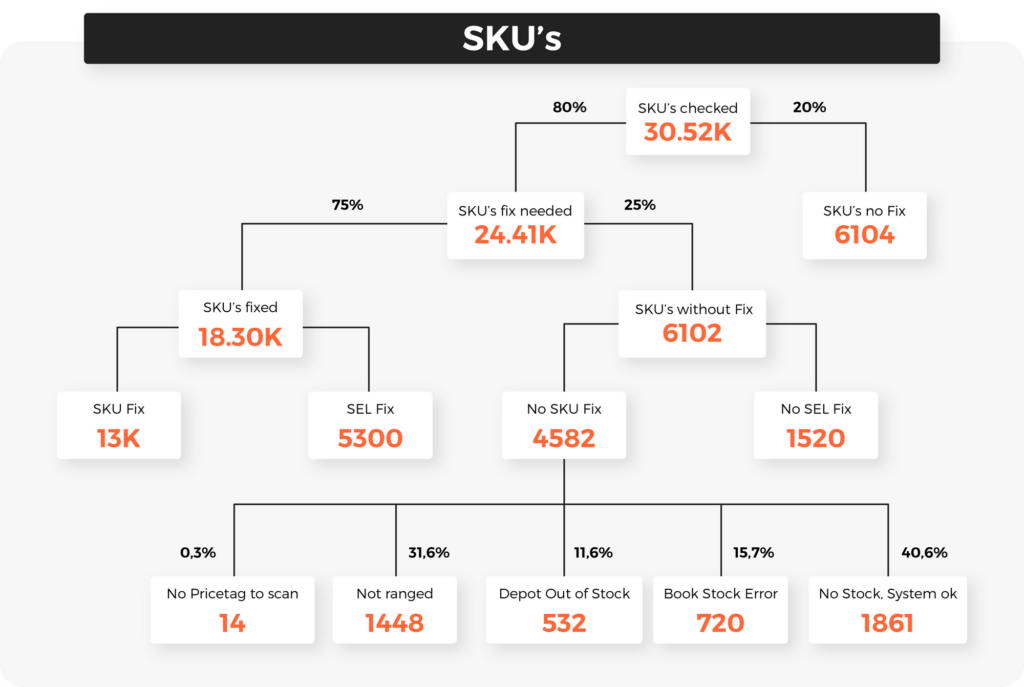
EPOS data – Case study
Imagine that your products are available in 600 stores.
In Store #12, your top SKU stops selling for 48 hours. The retailer’s system says it’s “in distribution.” To the head office, everything looks fine.
The Intervention: Your sales rep receives a signal and heads straight to Store #12. They find the shelf tag is missing. The staff “filled the gap” with a competitor’s product. No tag = no order = zero sales.
The rep fixes the tag, places the order, and sales resume instantly. The Hit Rate? In our current programs, the probability of a signal being a “true issue” is 80%.
Similar causes
Data reveals that the same issues happen repeatedly across your network:
• The “Gap Filler”: A staff member hides an out-of-stock by moving other products, effectively “deleting” your SKU from the shelf.
• Phantom Stock: Your system says there are 10 units. In reality, they were stolen or damaged. The system won’t reorder because it thinks the shelf is full.
• The Tag Ghost: No label, no scan, no revenue.
Always different stores
The hard truth? The stores that need you today won’t be the ones that need you tomorrow.
A rigid field team cannot keep up with data-driven signals. If your route is fixed, you’re ignoring the 80% of stores where the “Lost Sales Value” is highest.
To win, you need flexibility. Whether it’s retooling your internal team or using a crowdsourced partner. Agility is your only competitive advantage.
Want to learn more about how EPOS data can improve field sales?
Contact us to explore the possibilities!